
The Tongyi Qianwen mathematical model has a strong mathematical problem-solving ability. You can integrate the Tongyi Qianwen mathematical model into your business through the API interface call.
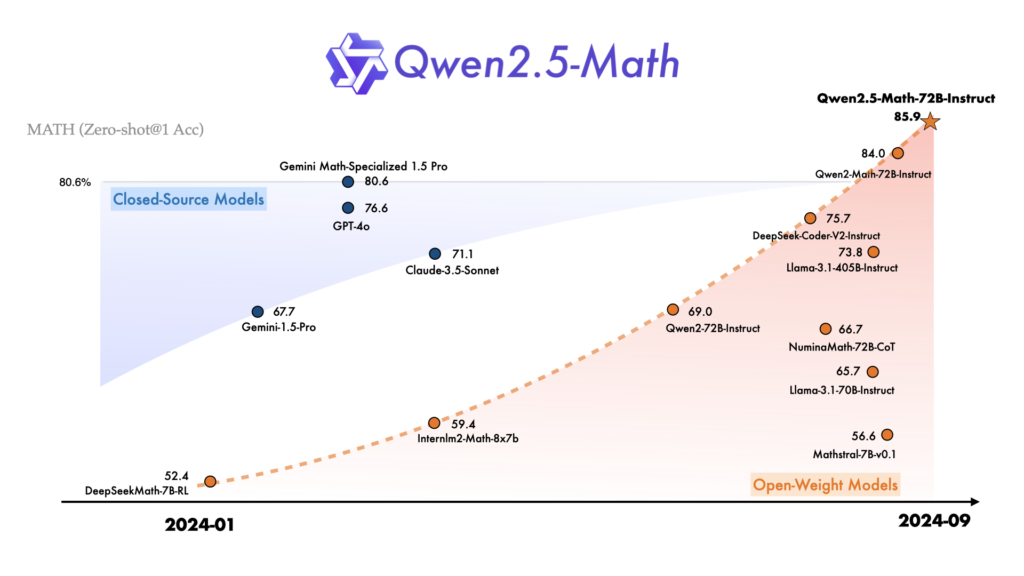
Unlike Qwen2-Math series which only supports using Chain-of-Thought (CoT) to solve English math problems, Qwen2.5-Math series is expanded to support using both CoT and Tool-integrated Reasoning (TIR) to solve math problems in both Chinese and English. The Qwen2.5-Math series models have achieved significant performance improvements compared to the Qwen2-Math series models on the Chinese and English mathematics benchmarks with CoT.
Overview of the model
| Model name | Context length | Maximum input | Maximum output | Input cost | Output cost | Free quota |
| (Number of Tokens) | (Per Thousand Token) | |||||
| Qwen-math-plus | 4,096 | 3,072 | 3,072 | 0.004 yuan | 0.012 yuan | 1 million TokenValidity period: 180 days after the opening of Bailian |
| Qwen-math-plus-latest | 0.004 yuan | 0.012 yuan | ||||
| Qwen-math-plus-0919 | 0.004 yuan | 0.012 yuan | ||||
| Qwen-math-plus-0816 | 0.004 yuan | 0.012 yuan | ||||
| Qwen-math-turbo | 0.002 yuan | 0.006 yuan | ||||
| Qwen-math-turbo-latest | 0.002 yuan | 0.006 yuan | ||||
| Qwen-math-turbo-0919 | 0.002 yuan | 0.006 yuan | ||||
Qwen-math-plus-latest, qwen-math-plus-0919, qwen-math-turbo, qwen-math-turbo-latest, qwen-math-turbo-091 The default System Content of the 9 model is “Please reason step by step, and put your final answer within \\\\boxed{}.”
For the flow limitation conditions of the model, please refer to Limit the flow.
Prerequisites
- Please refer to obtain API-KEY, open the Bailian service and obtain API-KEY.
- Please select the model you need to use in the model overview.
- You can use OpenAI Python SDK, DashScope SDK or HTTP interface to call the Tongyi Qianwen model. Please refer to the following methods to prepare your computing environment according to your needs.
If you have previously used OpenAI SDK and HTTP to call OpenAI services, you only need to adjust API-KEY, base_url, model and other parameters under the original framework, and you can directly call the Tongyi Qianwen mathematical model.
Call through OpenAI Python SDK
You can install or update OpenAI SDK through the following commands:
# 如果下述命令报错,请将pip替换为pip3 pip install -U openai
The base_url you need to configure is as follows: https://dashscope.aliyuncs.com/compatible-mode/v1
Compatibility through OpenAI-HTTP call
If you need to call through OpenAI-compatible HTTP, the complete access endpoint that needs to be configured is as follows:
POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions
Call through DashScope SDK
DashScope SDK provides two versions of Python and Java. Please refer to the installation SDK and install the latest version of the SDK.
Call through DashScope HTTP
If you need to call through DashScope’s HTTP method, you need to configure the complete access endpoint as follows:
POST https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation
We recommend that you configure API-KEY in the environment variable to reduce the risk of leakage of API-KEY. For details, please refer to the configuration of API-KEY to the environment variable. You can also configure API-KEY in the code, but there will be a risk of leakage.
Sample code
Tongyi Qianwen Mathematical Model is good at solving English mathematical problems. In your input problems, please use LaTex to represent mathematical symbols or formulas, such as:
$x$ 表示数学符号
$4x+5 = 6x+7$ 表示数学公式Taking the monadic equation as an example, I will show you the ability to experience the mathematical model of Tongyi Qianwen in mathematical problems through OpenAI or DashScope.
OpenAI is compatible with
DashScope
You can call the Tongyi Qianwen mathematical model through OpenAI SDK or OpenAI-compatible HTTP.
Python
curl
Sample code
from openai import OpenAI
import os
def get_response():
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"), # 如果您没有配置环境变量,请在此处用您的API Key进行替换
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 填写DashScope服务的base_url
)
completion = client.chat.completions.create(
model="qwen-math-plus",
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': 'Find the value of $x$ that satisfies the equation $4x+5 = 6x+7$.'}],
)
print(completion.model_dump_json())
if __name__ == '__main__':
get_response()Return the result
{
"id": "chatcmpl-f3b3102c-0e16-9718-9731-0a98fc69b50a",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "To solve the equation \\(4x + 5 = 6x + 7\\), we will follow a step-by-step approach to isolate the variable \\(x\\).\n\n1. **Subtract \\(4x\\) from both sides of the equation:**\n \\[\n 4x + 5 - 4x = 6x + 7 - 4x\n \\]\n Simplifying both sides, we get:\n \\[\n 5 = 2x + 7\n \\]\n\n2. **Subtract 7 from both sides of the equation:**\n \\[\n 5 - 7 = 2x + 7 - 7\n \\]\n Simplifying both sides, we get:\n \\[\n -2 = 2x\n \\]\n\n3. **Divide both sides by 2:**\n \\[\n \\frac{-2}{2} = \\frac{2x}{2}\n \\]\n Simplifying both sides, we get:\n \\[\n -1 = x\n \\]\n\nTherefore, the value of \\(x\\) that satisfies the equation is \\(\\boxed{-1}\\).",
"role": "assistant",
"function_call": null,
"tool_calls": null
}
}
],
"created": 1725357364,
"model": "qwen-math-plus",
"object": "chat.completion",
"service_tier": null,
"system_fingerprint": null,
"usage": {
"completion_tokens": 244,
"prompt_tokens": 42,
"total_tokens": 286
}
}Input and output parameters
You can view the input parameters and output parameters of different call methods through the table below. Among them, the meaning of each field in the data type column is as follows:
- string: string type.
- array: represents a list in Python and ArrayList in Java.
- integer: represents the integer type.
- float: floating point type.
- boolean: Boolean type.
- object: hash table.
OpenAI Python SDKOpenAI
Compatible with HTTPDashScope
SDKDashScope
HTTP
Input parameters
| Parameters | Type | Default value | Description |
| Model | String | – | The user uses the model parameter to indicate the corresponding model. |
| Messages | Array | – | The dialogue history between the user and the model. Each element in the array is in the form of {"role":角色, "content": 内容}. The current optional values of the role: system, user, assistant, among which, only the role is supported as system in messages[0]. In general, user and assistant need to appear alternately, and the last in messages The role of the element must be user. |
top_p(Optional) | Float | – | The probability threshold of the nuclear sampling method in the generation process, for example, when the value is 0.8, only the smallest set of the most likely tokens with a probability of more than or equal to 0.8 is retained as a candidate set. The value range is (0,1.0]. The larger the value, the higher the randomness generated; the lower the value, the higher the certainty generated. |
| temperature (optional) | Float | – | It is used to control the randomness and diversity of model responses. Specifically, the temperature value controls the degree to which the probability distribution of each candidate is smoothed when the text is generated. A higher temperature value will reduce the peak of the probability distribution, so that more low-probability words are selected and the generated results are more diverse; while a lower temperature value will enhance the peak of the probability distribution, making it easier for high-probability words to be selected and the generated results more certain.Value range: [0, 2), it is not recommended to take the value as 0, which is meaningless. |
| Presence_penalty(Optional) | Float | – | The repetition in the whole sequence when the user controls the model is generated. When increasing presence_penalty, it can reduce the repetition of model generation, and take the value range [-2.0, 2.0]. |
| max_tokens (optional) | Integer | – | Specify the maximum number of tokens that the model can generate. There are different upper limits depending on the model, generally no more than 2000. |
| Seed (optional) | Integer | – | The random number seeds used in the generation are used to control the randomness of the content generated by the model. Seed supports unsigned 64-bit integers. |
| stream (optional) | Boolean | False. | It is used to control whether to use streaming output. When the result is output in stream mode, the interface returns the result as generator, which needs to be obtained through iteration, and each output is the current generated incremental sequence. |
| stop (optional) | String or array | None. | The stop parameter is used to achieve precise control of the content generation process, and it automatically stops when the content generated by the model is about to contain the specified string or token_id. Stop can be a string type or array type.String typeStop when the model is about to generate the specified stop word.For example, if you specify stop as “Hello”, the model will stop when it is about to generate “Hello”.Array typeThe element in the array can be token_id or string, or the element can be the array of token_id. When the token to be generated by the model or its corresponding token_id is in stop, the model generation will stop. The following is an example of when stop is array (the tokenizer corresponding model is qwen-turbo):1. The element is token_id:If the token_id is 108386 and 104307, the token is “Hello” and “Weather” respectively. If the stop is set to [108386,104307], the model will stop when it generates “Hello” or “Weather”.Two. The element is a string:If you set stop to ["你好","天气"], the model will stop when it generates “Hello” or “Weather”.3. The element is array:token_id is 108386 and 103924 corresponds to “Hello” and “Ah” respectively, and token_id is 35946 and 101243 corresponds to “I” and “very good” respectively. If you set stop to [[108386, 103924],[35946, 101243]], the model will stop when it generates “Hello” or “I’m fine”.DescriptionWhen stop is an array type, token_id and string cannot be entered as elements at the same time. For example, stop cannot be specified as ["你好",104307]. |
| tools (optional) | Array | None. | DescriptionThe mathematical model of Tongyi Qianwen is weak for calling tools such as function call. It is not recommended to use the mathematical model of Tongyi Qianwen for function call; if you need to use the function call ability, it is recommended to use a general text model.It is used to specify the tool library that can be called by the model, and the function call process model will select one of the tools from it. The structure of each tool in tools is as follows:type, the type is string, indicating the type of tools. Currently, only function is supported.Function, the type is object, and the key values include name, description and parameters:name: The type is string, which represents the name of the tool function. It must be letters and numbers, and can contain underscores and short lines. The maximum length is 64.Description: The type is string, which represents the description of the tool function, so that the model can choose when and how to call the tool function.Parameters: The type is object, which represents the parameter description of the tool, which needs to be a legitimate JSON Schema. The description of JSON Schema can be found in the link. If the parameters are empty, it means that the function is not included.In the function call process, whether it is the rotation of initiating the function call or submitting the execution results of the tool function to the model, the tools parameters need to be set. |
| stream_options (optional) | Object | None. | This parameter is used to configure whether to display the number of tokens used during streaming output. Only when the stream is True will the parameter be activated and effective. If you need to count the number of tokens in streaming output mode, you can configure the parameter to stream_options={"include_usage":True}. |
Description of the exit
| Return parameters | Data type | Description | Remarks |
| Id | String | The id generated by the system identifies this call. | None |
| Model | String | The model name of this call. | None |
| System_fingerprint | String | The configuration version used when the model is running is not supported at present, and it is returned as an empty string “”. | None |
| choices | Array | Details of the content generated by the model. | None |
| choices[i].finish_reason | String | There are three situations:It is null when it is being generated;Ends as stop because the stop condition in the input parameter is triggered;It ends with length because the growth is too long. | |
| choices[i].message | Object | The message output by the model. | |
| choices[i].message.role | String | The role of the model is fixed as assistant. | |
| choices[i].message.content | String | The text generated by the model. | |
| choices[i].index | Integer | The sequence number of the generated results is 0 by default. | |
| Created | Integer | The time stamp (s) of the current generated result. | None |
| Usage | Object | The measurement information indicates the token data consumed by this request. | None |
| Usage.prompt_tokens | Integer | The length after the user enters the text to the token. | You can refer to the mutual conversion between strings and tokens to estimate the token. |
| Usage.completion_tokens | Integer | The length after the model generated reply is converted into token. | None |
| Usage.total_tokens | Integer | The sum of usage.prompt_tokens and usage.completion_tokens. | None |